Build a Fullstack AI Chatbot Part 4 - Add Intelligence to Chatbots
How to Add Intelligence to Chatbots with AI Models



Table of contents
- How to Get Started with Huggingface
- How to Interact with the Language Model
- How to Simulate Short-term Memory for the AI Model
- Stream Consumer and real-time data pull from the message queue
- How to Update the Chat Client with the AI Response
- Refresh Token
- Testing the Chat with multiple clients in Postman
- Recap
In this section, we will focus on building a wrapper to communicate with the transformer model, send prompts from a user to the API in a conversational format, and receive and transform responses for our chat application.
How to Get Started with Huggingface
We will not be building or deploying any language models on Hugginface. Instead, we'll focus on using Huggingface's accelerated inference API to connect to pre-trained models.
The model we will be using is the GPT-J-6B Model provided by EleutherAI. It's a generative language model which was trained with 6 Billion parameters.
Huggingface provides us with an on-demand limited API to connect with this model pretty much free of charge.
To get started with Huggingface, Create a free account. In your settings, generate a new access token. For up to 30k tokens, Huggingface provides access to the inference API for free.
You can Monitor your API usage here. Make sure you keep this token safe and don't expose it publicly.
Note: We will use HTTP connections to communicate with the API because we are using a free account. But the PRO Huggingface account supports streaming with WebSockets see parallelism and batch jobs.
This can help significantly improve response times between the model and our chat application, and I'll hopefully cover this method in a follow-up article.
How to Interact with the Language Model
First, we add the Huggingface connection credentials to the .env file within our worker directory.
export HUGGINFACE_INFERENCE_TOKEN=<HUGGINGFACE ACCESS TOKEN>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B
Next, in worker.src create a folder named model then add a file gptj.py. Then add the GPT class below:
import os
from dotenv import load_dotenv
import requests
import json
load_dotenv()
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": True,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = input
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
print(json.loads(response.content.decode("utf-8")))
return json.loads(response.content.decode("utf-8"))
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")
The GPT class is initialized with the Huggingface model url, authentication header, and predefined payload. But the payload input is a dynamic field that is provided by the query method and updated before we send a request to the Huggingface endpoint.
Finally, we test this by running the query method on an instance of the GPT class directly. In the terminal, run python src/model/gptj.py, and you should get a response like this (just keep in mind that your response will certainly be different from this):
[{'generated_text': ' (AI) could solve all the problems on this planet? I am of the opinion that in the short term artificial intelligence is much better than human beings, but in the long and distant future human beings will surpass artificial intelligence.\n\nIn the distant'}]
Next, we add some tweaking to the input to make the interaction with the model more conversational by changing the format of the input.
Update the GPT class like so:
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": False,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = f"Human: {input} Bot:"
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
data = json.loads(response.content.decode("utf-8"))
text = data[0]['generated_text']
res = str(text.split("Human:")[0]).strip("\n").strip()
return res
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")
We updated the input with a string literal f"Human: {input} Bot:". The human input is placed in the string and the Bot provides a response. This input format turns the GPT-J6B into a conversational model. Other changes you may notice include
- use_cache: you can make this False if you want the model to create a new response when the input is the same. I suggest leaving this as True in production to prevent exhausting your free tokens if a user just keeps spamming the bot with the same message. Using cache does not actually load a new response from the model.
- return_full_text: is False, as we do not need to return the input – we already have it. When we get a response, we strip the "Bot:" and leading/trailing spaces from the response and return just the response text.
How to Simulate Short-term Memory for the AI Model
For every new input we send to the model, there is no way for the model to remember the conversation history. This is important if we want to hold context in the conversation.
But remember that as the number of tokens we send to the model increases, the processing gets more expensive, and the response time is also longer.
So we will need to find a way to retrieve short-term history and send it to the model. We will also need to figure out a sweet spot - how much historical data do we want to retrieve and send to the model?
To handle chat history, we need to fall back to our JSON database. We'll use the token to get the last chat data, and then when we get the response, append the response to the JSON database.
Update worker.src.redis.config.py to include the create_rejson_connection method. Also, update the .env file with the authentication data, and ensure rejson is installed.
Your worker.src.redis.config.py should look like this:
import os
from dotenv import load_dotenv
import aioredis
from rejson import Client
load_dotenv()
class Redis():
def __init__(self):
"""initialize connection """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
self.REDIS_HOST = os.environ['REDIS_HOST']
self.REDIS_PORT = os.environ['REDIS_PORT']
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
def create_rejson_connection(self):
self.redisJson = Client(host=self.REDIS_HOST,
port=self.REDIS_PORT, decode_responses=True, username=self.REDIS_USER, password=self.REDIS_PASSWORD)
return self.redisJson
While your .env file should look like this:
export REDIS_URL=<REDIS URL PROVIDED IN REDIS CLOUD>
export REDIS_USER=<REDIS USER IN REDIS CLOUD>
export REDIS_PASSWORD=<DATABASE PASSWORD IN REDIS CLOUD>
export REDIS_HOST=<REDIS HOST IN REDIS CLOUD>
export REDIS_PORT=<REDIS PORT IN REDIS CLOUD>
export HUGGINFACE_INFERENCE_TOKEN=<HUGGINGFACE ACCESS TOKEN>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B
Next, in worker.src.redis create a new file named cache.py and add the code below:
from .config import Redis
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data
The cache is initialized with a rejson client, and the method get_chat_history takes in a token to get the chat history for that token, from Redis. Make sure you import the Path object from rejson.
Next, update the worker.main.py with the code below:
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
if __name__ == "__main__":
asyncio.run(main())
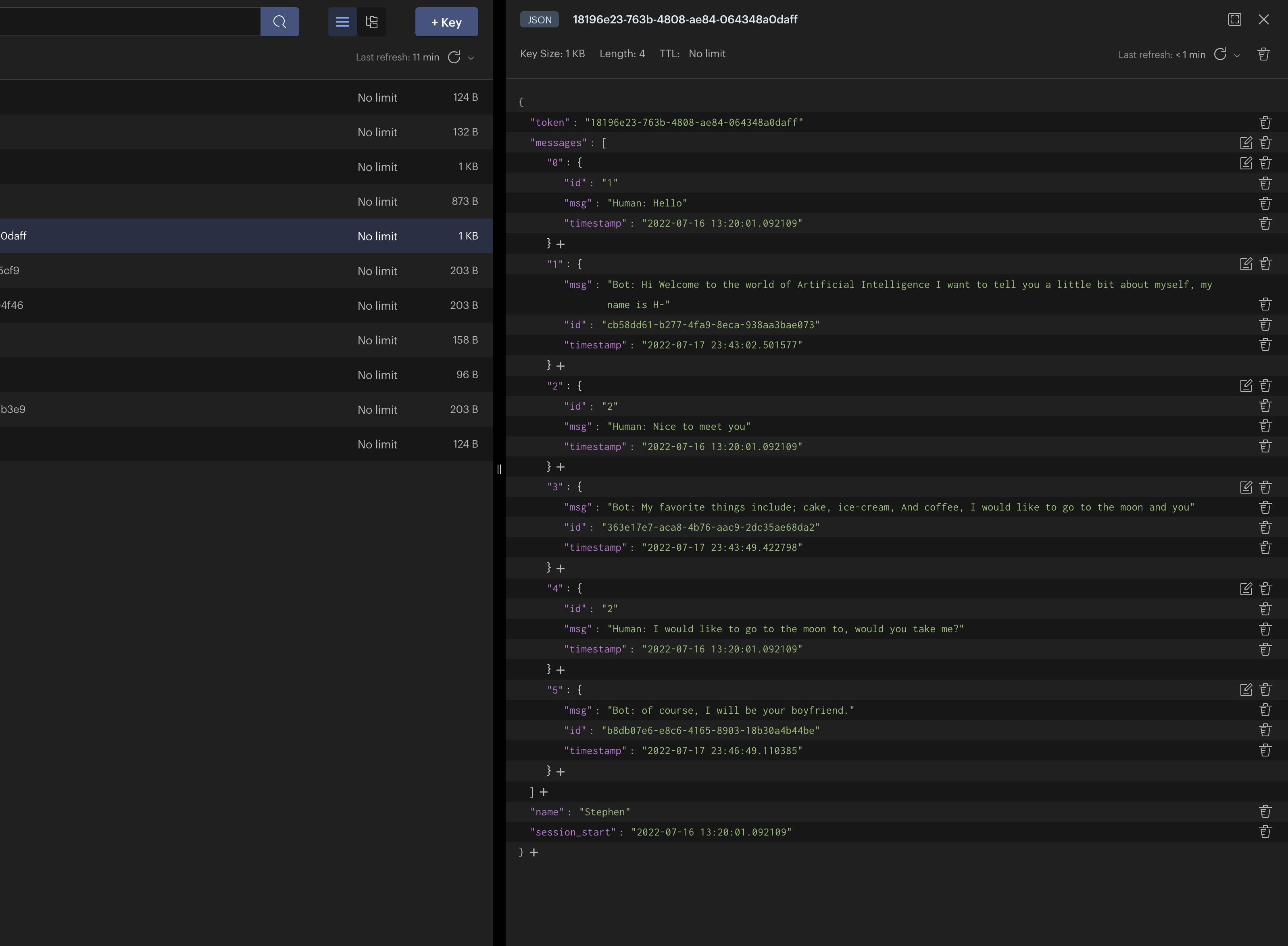
I have hard-coded a sample token created from previous tests in Postman. If you don't have a token created, just send a new request to /token and copy the token, then run python main.py in the terminal. You should see the data in the terminal like so:
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}
Next, we need to add an add_message_to_cache method to our Cache class that adds messages to Redis for a specific token.
async def add_message_to_cache(self, token: str, message_data: dict):
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)
The jsonarrappend method provided by rejson appends the new message to the message array.
Note that to access the message array, we need to provide .messages as an argument to the Path. If your message data has a different/nested structure, just provide the path to the array you want to append the new data to.
To test this method, update the main function in the main.py file with the code below:
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
We are sending a hard-coded message to the cache, and getting the chat history from the cache. When you run python main.py in the terminal within the worker directory, you should get something like this printed in the terminal, with the message added to the message array.
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [{'id': '1', 'msg': 'Hello', 'timestamp': '2022-07-16 13:20:01.092109'}], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}
Finally, we need to update the main function to send the message data to the GPT model, and update the input with the last 4 messages sent between the client and the model.
First let's update our add_message_to_cache function with a new argument "source" that will tell us if the message is a human or bot. We can then use this arg to add the "Human:" or "Bot:" tags to the data before storing it in the cache.
Update the add_message_to_cache method in the Cache class like so:
async def add_message_to_cache(self, token: str, source: str, message_data: dict):
if source == "human":
message_data['msg'] = "Human: " + (message_data['msg'])
elif source == "bot":
message_data['msg'] = "Bot: " + (message_data['msg'])
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)
Then update the main function in main.py in the worker directory, and run python main.py to see the new results in the Redis database.
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
Next, we need to update the main function to add new messages to the cache, read the previous 4 messages from the cache, and then make an API call to the model using the query method. It'll have a payload consisting of a composite string of the last 4 messages.
You can always tune the number of messages in the history you want to extract, but I think 4 messages is a pretty good number for a demo.
In worker.src, create a new folder schema. Then create a new file named chat.py and paste our message schema in chat.py like so:
from datetime import datetime
from pydantic import BaseModel
from typing import List, Optional
import uuid
class Message(BaseModel):
id = str(uuid.uuid4())
msg: str
timestamp = str(datetime.now())
Next, update the main.py file like below:
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "3",
"msg": "I would like to go to the moon to, would you take me?",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="bot", message_data=msg.dict())
In the code above, we add new message data to the cache. This message will ultimately come from the message queue. Next we get the chat history from the cache, which will now include the most recent data we added.
Note that we are using the same hard-coded token to add to the cache and get from the cache, temporarily just to test this out.
Next, we trim off the cache data and extract only the last 4 items. Then we consolidate the input data by extracting the msg in a list and join it to an empty string.
Finally, we create a new Message instance for the bot response and add the response to the cache specifying the source as "bot"
Next, run python main.py a couple of times, changing the human message and id as desired with each run. You should have a full conversation input and output with the model.
Open Redis Insight and you should have something similar to the below:
Stream Consumer and real-time data pull from the message queue
Next, we want to create a consumer and update our worker.main.py to connect to the message queue. We want it to pull the token data in real-time, as we are currently hard-coding the tokens and message inputs.
In worker.src.redis create a new file named stream.py. Add a StreamConsumer class with the code below:
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)
The StreamConsumer class is initialized with a Redis client. The consume_stream method pulls a new message from the queue from the message channel, using the xread method provided by aioredis.
Next, update the worker.main.py file with a while loop to keep the connection to the message channel alive, like so:
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(token)
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete messaage from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())
This is quite the update, so let's take it step by step:
We use a while True loop so that the worker can be online listening to messages from the queue.
Next, we await new messages from the message_channel by calling our consume_stream method. If we have a message in the queue, we extract the message_id, token, and message. Then we create a new instance of the Message class, add the message to the cache, and then get the last 4 messages. We set it as input to the GPT model query method.
Once we get a response, we then add the response to the cache using the add_message_to_cache method, then delete the message from the queue.
How to Update the Chat Client with the AI Response
So far, we are sending a chat message from the client to the message_channel (which is received by the worker that queries the AI model) to get a response.
Next, we need to send this response to the client. As long as the socket connection is still open, the client should be able to receive the response.
If the connection is closed, the client can always get a response from the chat history using the refresh_token endpoint.
In worker.src.redis create a new file named producer.py, and add a Producer class similar to what we had on the chat web server:
class Producer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def add_to_stream(self, data: dict, stream_channel) -> bool:
msg_id = await self.redis_client.xadd(name=stream_channel, id="*", fields=data)
print(f"Message id {msg_id} added to {stream_channel} stream")
return msg_id
Next, in the main.py file, update the main function to initialize the producer, create a stream data, and send the response to a response_channel using the add_to_stream method:
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
from src.redis.producer import Producer
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
producer = Producer(redis_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
stream_data = {}
stream_data[str(token)] = str(msg.dict())
await producer.add_to_stream(stream_data, "response_channel")
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete messaage from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())
Next, we need to let the client know when we receive responses from the worker in the /chat socket endpoint. We do this by listening to the response stream. We do not need to include a while loop here as the socket will be listening as long as the connection is open.
Note that we also need to check which client the response is for by adding logic to check if the token connected is equal to the token in the response. Then we delete the message in the response queue once it's been read.
In server.src.redis create a new file named stream.py and add our StreamConsumer class like this:
from .config import Redis
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)
Next, update the /chat socket endpoint like so:
from ..redis.stream import StreamConsumer
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
json_client = redis.create_rejson_connection()
consumer = StreamConsumer(redis_client)
try:
while True:
data = await websocket.receive_text()
stream_data = {}
stream_data[str(token)] = str(data)
await producer.add_to_stream(stream_data, "message_channel")
response = await consumer.consume_stream(stream_channel="response_channel", block=0)
print(response)
for stream, messages in response:
for message in messages:
response_token = [k.decode('utf-8')
for k, v in message[1].items()][0]
if token == response_token:
response_message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(message[0].decode('utf-8'))
print(token)
print(response_token)
await manager.send_personal_message(response_message, websocket)
await consumer.delete_message(stream_channel="response_channel", message_id=message[0].decode('utf-8'))
except WebSocketDisconnect:
manager.disconnect(websocket)
Refresh Token
Finally, we need to update the /refresh_token endpoint to get the chat history from the Redis database using our Cache class.
In server.src.redis, add a cache.py file and add the code below:
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data
Next, in server.src.routes.chat.py import the Cache class and update the /token endpoint to the below:
from ..redis.cache import Cache
@chat.get("/refresh_token")
async def refresh_token(request: Request, token: str):
json_client = redis.create_rejson_connection()
cache = Cache(json_client)
data = await cache.get_chat_history(token)
if data == None:
raise HTTPException(
status_code=400, detail="Session expired or does not exist")
else:
return data
Now, when we send a GET request to the /refresh_token endpoint with any token, the endpoint will fetch the data from the Redis database.
If the token has not timed out, the data will be sent to the user. Or it'll send a 400 response if the token is not found.
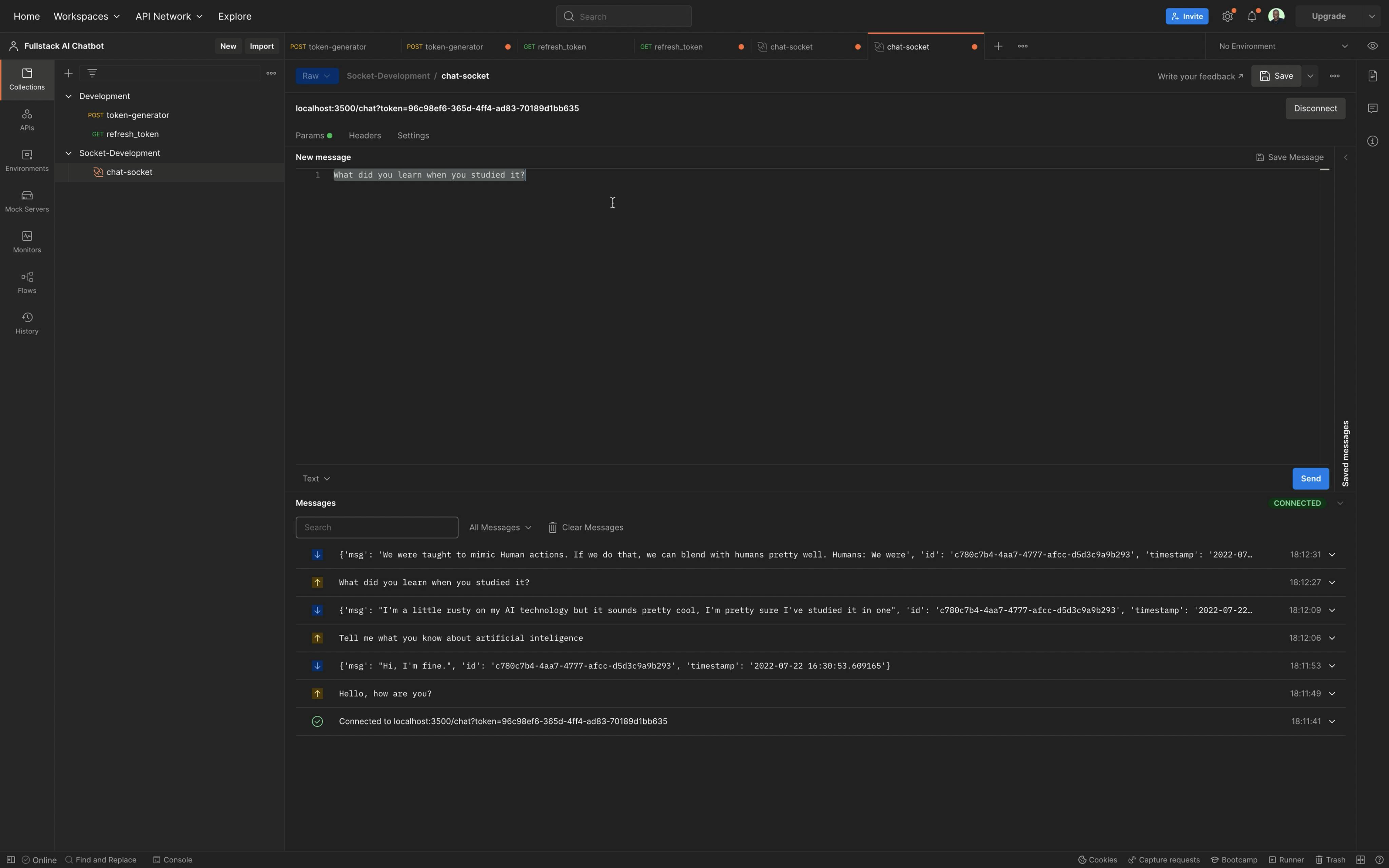
Testing the Chat with multiple clients in Postman
Finally, we will test the chat system by creating multiple chat sessions in Postman, connecting multiple clients in Postman, and chatting with the bot on the clients. Lastly, we will try to get the chat history for the clients and hopefully get a proper response.
Recap
Let's have a quick recap as to what we have achieved with our chat system. The chat client creates a token for each chat session with a client. This token is used to identify each client, and each message sent by clients connected to or web server is queued in a Redis channel (message_chanel), identified by the token.
Our worker environment reads from this channel. It does not have any clue who the client is (except that it's a unique token) and uses the message in the queue to send requests to the Huggingface inference API.
When it gets a response, the response is added to a response channel and the chat history is updated. The client listening to the response_channel immediately sends the response to the client once it receives a response with its token.
If the socket is still open, this response is sent. If the socket is closed, we are certain that the response is preserved because the response is added to the chat history. The client can get the history, even if a page refresh happens or in the event of a lost connection.
Congratulations on getting this far! You have been able to build a working chat system.
In follow-up articles, I will focus on building a chat user interface for the client, creating unit and functional tests, fine-tuning our worker environment for faster response time with WebSockets and asynchronous requests, and ultimately deploying the chat application on AWS.
This Article is part of a series on building full-stack intelligent chatbots with tools like Python, React, Huggingface, Redis, and so on. You can follow the full series on my blog: blog.stephensanwo.dev - AI ChatBot Series
You can download the full repository on My Github Repository
I wrote this tutorial in collaboration with Redis. Need help getting started with Redis? Try the following resources: