Open Workflow
What is Open Workflow?
Open Workflow is an open source low-code analytics automation workflow, that decouples monolithic analytics projects into re-usable functional components that can be chained together to solve a problem. It provides a seamless platform for developers to deploy modular functions that can be re-used by other developers, analysts and non-coders for automated analytics and robotic process automation (RPA).
Open Workflow improves the collaboration between business process owners (who are typically non-coders), and developers, by providing an infrastructure where developers can share pre-written functions, targeted at solving specific use cases, which consumers can then mix and match while building their workflows using a simple user interface.
Having worked in analytics and automation for some really complex use cases, Multilayered analytics can become complex and tedious quickly. A useful approach will be to break down the analytics into modular functions that can be called anytime. These functions may be built by you or some other person, but the very basic principle is that the function will take an input of a range of data structures and return an output. These functions can then be mixed and matched in multiple ways to create a workflow that solves a specific problem. For example, a simple reconciliation work flow between two different data sources could involve the following:
Each of these work steps can be created as simple functions and chained together in a workflow that can run on a monthly basis.
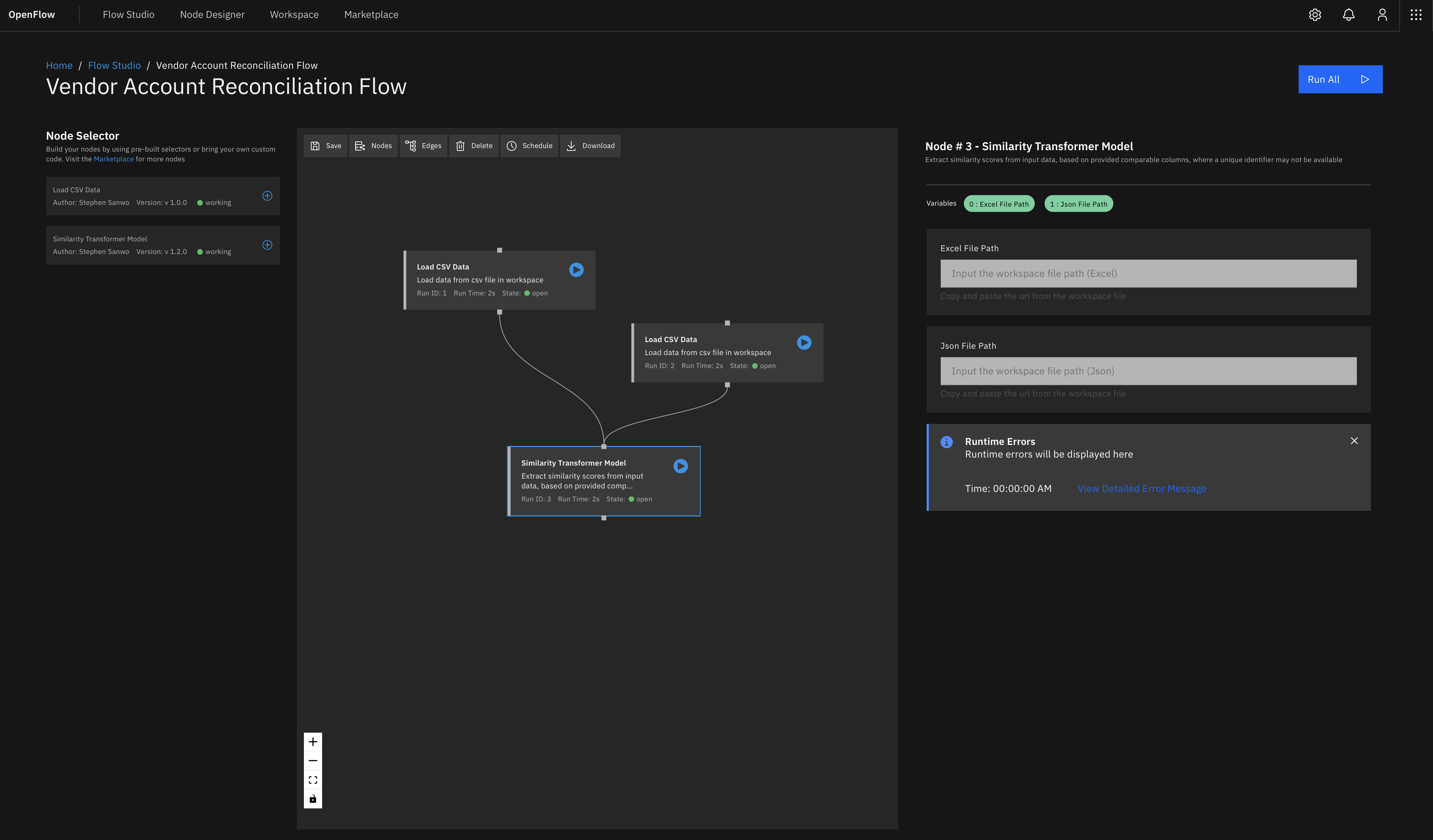
With Open Workflow, developers can create re-usable functions, and wrap them with a simple user interface, where consumers can easily provide the variables required by those functions, and chain these functions together a s part of a larger workflow. For example, the reconciliation workflow will have 4 functions for each step, two of which are not necessarily related to a reconciliation procedure itself (extracting data from source systems and sending reports to an email address)
A business owner (consumer) can provide the required variables to run the workflow and reuse, batch or schedule data operations. From a developer point of view, you wouldn’t need to provide an API or use a tool like streamlit for every application you want some users to consume. You can embed your functions in Open Workflow and mix and match the logic for your workflow as you wish. From a business owner point of view, you have the flexibility to go beyond a preset workflow logic set by the developer and construct your own logic.
How it Works
Open Workflow is a collection of worfklows that solve an analytics problem or automates a process. The basic unit of a flow is the node and you can have infinite nodes in a flow. Nodes are essentially functions that take an input and generate an output. The output is either passed on to a subsequent node, multiple subsequent nodes, or as a final output. A node can also either be a component node or a code node.
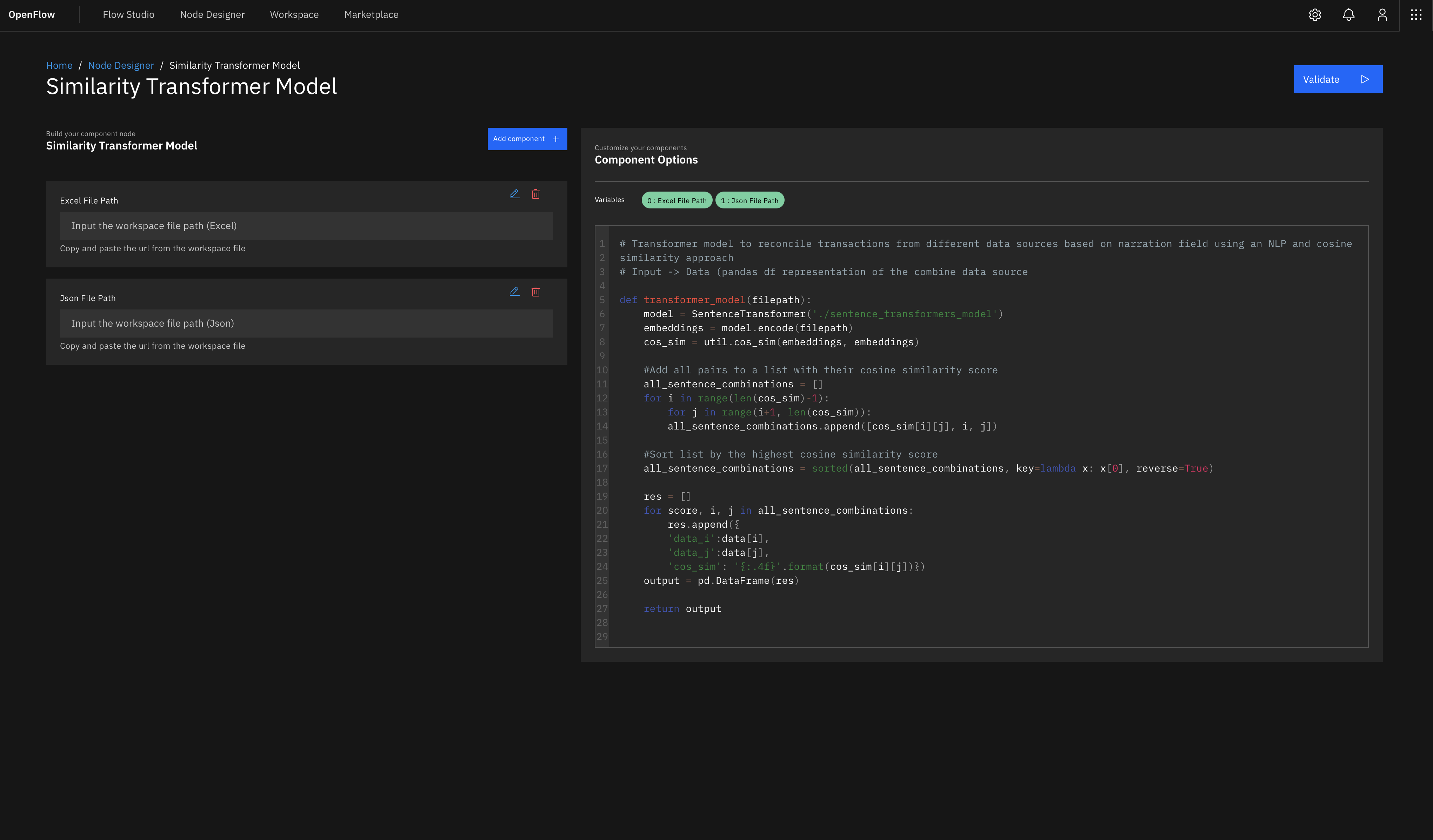
A component node is a function has been pre built and tested by a contributor and it provides a simple user interface to interact with it. You have little or no flexibility with component nodes. For example, grouping a data frame can be a component node, if all the required variables are converted to input dialogs or a simple key-value input.
Nodes communicate with each other through the edges. nodes will always run in a sequential order except a node is called directly and it does not depend on an output from another node. Selecting a node opens up an actions pane, the configuration of the actions pane will vary depending on if the node is a component node or a code node. Component nodes will have a user interface for inputs, the code nodes however will have a code interface with more flexibility to control and alter the underlying code directly
Software Architecture
At a high level the user will interact with Open Workflow through the client built in React (TypeScript), with IBM Carbon as the design system. The API Gateway that serves API calls from and to the client is built in GO, and just serves as a proxy between the client and the background processing queues.
For compiling the python code and testing in-browser, I will be exploring Pyiodie and WASM. This will help in scaling across to users, and only sever-based scheduled workflows will require a python server environment. This obviously has to be implemented as a background task with service workers, so as not to disrupt the main browser thread. There probably could be a feature add-on that will support in-browser Go and JavaScript.
For the backend processing task queues, Its a choce between Apache Kafka and Redis, I'm however leaning towards Redis. I intend to spin up nodes that have been pre configured with python environments. For metadata storage, I will use a PostgreSQL database and a Redis cache. Things may change in the future. And I will continue to write about this journey and why I have decided to go for which technologies I use.
Obviously there is the question of scaling. In-browser compilation with WASM will definitely reduce the load on the python nodes. However, Pyiodie and WASM do not support all python libraries yet so there has to be python nodes that can be spun up by the users. While this is intended to be a deploy-on-your-own docker compose workflow, I believe there is also a possiblity of a scalable cloud option in the future.
Contribute
To contribute, check out the github repository at https://github.com/stephensanwo/open-workflow